


1. Data, cut me some slack
A year ago, my co-founder and I closed an initiative that had no future.
But a fact still was in our minds, one that felt almost too bad to be true: 85% of AI products in the enterprise fail to move from proof of concept to production.
That stat hit us like a punch. How could something as transformative and hyped as AI still struggle to deliver inside the enterprise? How could a technology that’s reshaping industries and driving entire markets be such a poor fit where it’s arguably needed most?
There must be a serious problem, we thought.
Then, in October, Davide shared a post from Sequoia’s Sonya Wang and Path Grady: “Generative AI’s Act o1.” It gave an input, and we wrote Human-in-the-Loop, where we tried to understand the role of data in a world where humans were starting to work heavily along responsive models like ChatGPT.
After that, we started experimenting. The CTO scrapped ML models and the data we had from the previous venture, while I started talking with potential investors and peers about a new company we had in mind to get a sort of sentiment.
By the end of December, I stumbled on EQT Ventures’ article about Knowledge Graphs and LLMs, and in January, for one month, we studied to answer a provocative question: what is the best data soil for AI to thrive? Resulting in an article titled “Foundational Data Layer.”
After that, we did what builders do: we locked in. We talked to developers, data scientists, and business leads. We gathered notes, annotated meetings, tested assumptions, and tried to trace the patterns behind the very initial question. Why AI fails so much.
I’ll spare you the full mess of scribbles, but here’s what we found: the true bottleneck isn’t model quality. It isn’t compute. It isn’t even a lack of AI talent (this is at number two.)
It’s data.
Data is the constant in every failed system. It’s always there, but rarely ready. It’s structured for reporting, human comprehension, not for AI’s needs. Fragmented across silos and again, completely mismatched with how AI needs to operate.
This was our starting point. From that one alarming statistic, we uncovered a deeper systemic gap, and it became the foundation for what we’re now building.
Right now, most companies are trying to drive supercars on a running track.
2. Oil and shovels
If data is still “the new oil,” and we’re now in the middle of an AI gold rush, then data isn’t just the oil: it’s the shovel, too. It’s the raw fuel powering every AI engine and the pickaxe in the hands of every modern-day prospector. If you’re not sitting on a pile of structured, actionable data, or better yet, building the tools to make sense of it, you’re not in the game. You’re just trying. And sure, maybe that sounds dramatic, but look around.
The companies that focused early on creating and enabling high-quality data infrastructure? They are thriving.
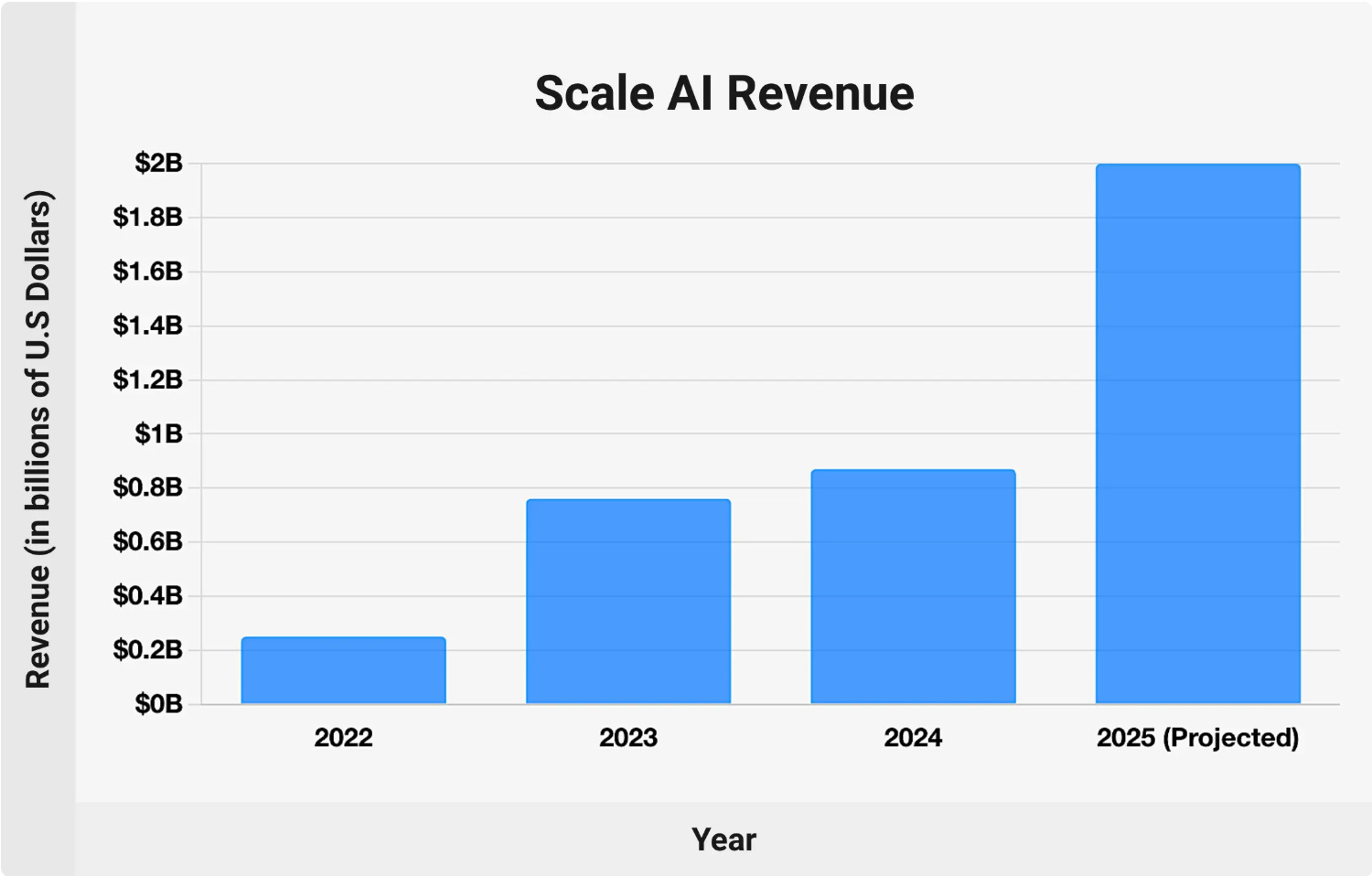
Take Scale AI, for example. It’s projecting a massive jump in financial performance, with revenue expected to more than double in 2025, hitting $2 billion, up from roughly $870 million in 2024. That kind of acceleration is powering a potential tender offer that could value the company at up to $25 billion, a sharp climb from its $13.8 billion valuation at Series F. The message is clear: investors see Scale AI as central to the modern AI stack.
Or Palantir, whose CEO is famously obsessed with the word ontology and products that work like magic. In 2024, the company grew revenue by 29% to $2.87 billion and posted a $462 million GAAP profit. U.S. commercial revenue alone jumped 54% to $702 million. For 2025, Palantir expects revenue to hit up to $3.76 billion, a 31% increase, driven by strong demand across both government and private sectors, especially in AI-powered operations.
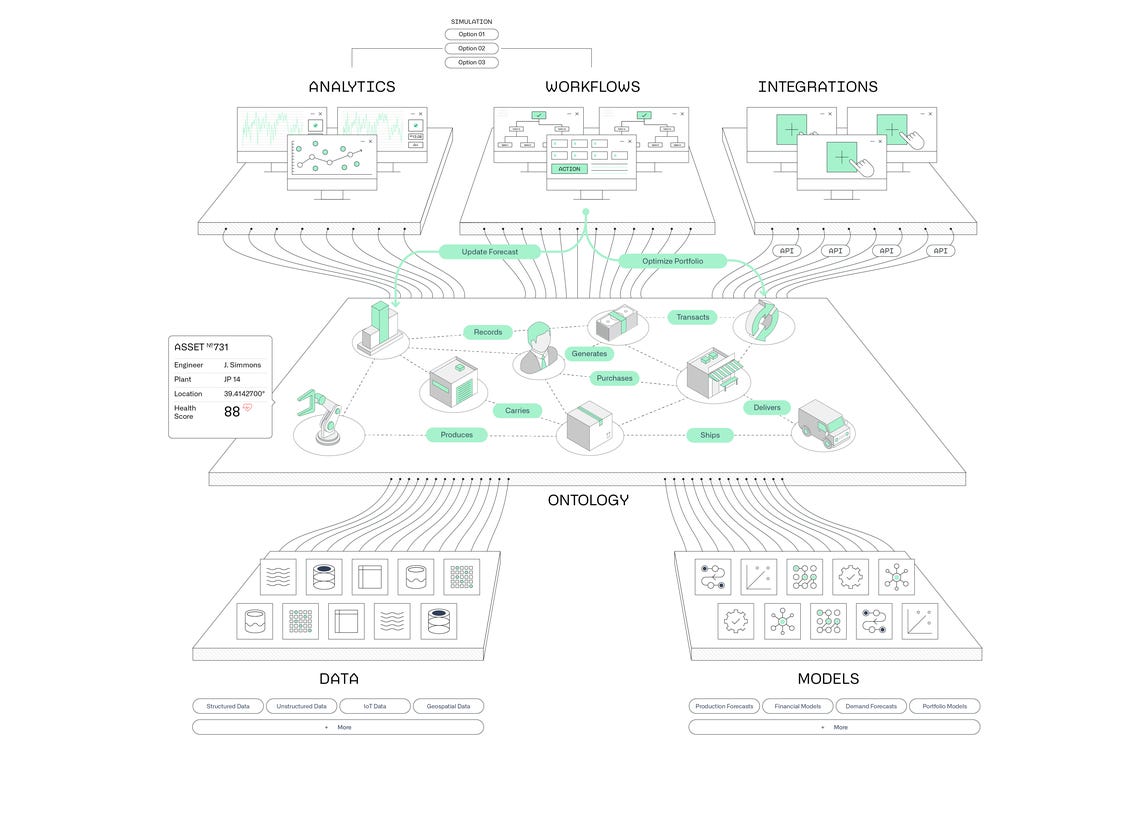
And then there’s Neo4j, the graph database pioneer that quietly crossed $200 million in ARR. It’s not just growing, it’s powering real transformation, e.g., as the backbone for Klarna’s latest AI-driven overhaul.
In short, the companies building serious data infrastructure aren’t just supporting the AI boom; they are defining it. To me, it sounds like validation.
3. Why autonomous cars now?
Given that, we started from what seemed obvious: data is the biggest point of friction for AI to work in the enterprise, but we wanted to go deeper, looking for opportunities.
After running through the notes and looking at various industries, the answer became clear: there’s an entire layer of enterprise data that is still locked inside dashboards and PowerPoints, a layer so outdated, it’s not only limiting AI, but also humans in making great decisions and actions.
That layer is the context: the situational awareness that explains why things are happening, not just what is happening.
Contextual data means everything that sits outside the company’s core systems but critically shapes its success: market signals, customer behavior, local events, competitive shifts, regulatory changes, social sentiment, and more. It’s the live, real-world information that gives meaning to operational data, but that is rarely connected, structured, or made machine-readable.
It was clear that enterprise leaders want to expand the use of AI in autonomous decision-making and execution, not just dashboards or assistants, but systems that can reason and act to improve operations in response to a changing world, customers, and users.
But this is not easily possible.
There is no platform today that builds a machine-actionable representation of a company’s environment, one that allows AI to “see” beyond internal databases and take action accordingly.
In other words:
Would you trust a self-driving car that doesn’t know what’s happening around it? A car that follows only a static map, data collected periodically, without a real-time complete perception of the outside world?
Probably not.
And yet, that’s how most companies are approaching AI in operations today, with models that lack the context needed to make real decisions.
It starts with perception.
4. Companies like Wayve Cars

For the ones who lived under a rock, Wayve is a British company shaking up the self-driving space. No clunky rules or HD maps: just pure, end-to-end AI that learns to drive from real-world data. It’s bold, it’s modern, and honestly, it’s exactly how we think next-gen enterprises should work, too. It looks like a system that perceives, decides, and acts without waiting for permission.
But here’s the catch: just like in self-driving cars, the data layer that fuels the autonomous enterprise needs three pillars to work properly:
1. Perception Systems
If a self-driving car can’t see the road, it crashes. The same is true for the autonomous enterprise: without a perception system that captures what’s happening outside, it has no chance of operating safely or intelligently. Most companies still navigate with internal data only: no live market signals, no behavioral feedback from customers, no structured context about the real world. It’s like trying to drive blindfolded, with a static map from last quarter. That’s why perception is the first critical layer of the autonomous company. It enables awareness.
And while many incumbents (research firms) are still squinting in the dark, a new generation of companies is setting the pace. We’re particularly excited about Listen Labs: exactly the kind of input our infrastructure is built to ingest.
2. Data Integration for Decision and Control
In autonomous vehicles, cameras, LIDAR, and GPS don’t work in isolation; they fuse into a single model of the world so the system can reason, decide, and act. The same must happen inside an autonomous enterprise. Internal data needs to be integrated with external signals to form a coherent operational context. When a company is running on autopilot, disconnected systems are a risk. If your AI can’t stitch context to control, it can’t make real-time decisions or adapt to change. You wouldn’t let a car on the road that can’t respond to traffic. Why should your business be any different?
3. Think of AI as an End-User
A self-driving car doesn’t need a dashboard. It doesn’t need gauges or a windshield. That’s for the human passenger. The AI system navigates using structured, high-resolution data, and the autonomous AI is the same. It doesn’t benefit from more dashboards or polished PowerPoints. If we want autonomy, we need to design data systems for machines, not analysts. The priority is clean, connected, machine-readable data that lets AI act independently. Interfaces are still critical, but for trust, communication, and control by humans, not for feeding the AI itself.
5. Now, Build
I’m not the best at writing conclusions, especially when the story is still unfolding.
So, where does this leave us?
We started by exploring the role of humans in the AI loop. Then we uncovered the roots of AI’s enterprise headaches. Then we discovered that data companies deliver results. Then we unveiled the right data. And ultimately, we began structuring that data.
Now, I truly believe this will unlock a whole new way for humans and AI to collaborate and to interact with their organizations.
Like is happening with cars.
AI adoption isn’t optional anymore, and we’re moving with urgency. Because just like with autonomous driving, if machines are going to chauffeur you around, and you’re going to be an active passenger, you want to be 100% confident that the map is not a decade old. Right?
Well, buckle up, it’s happening soon.